
Properties
SQL
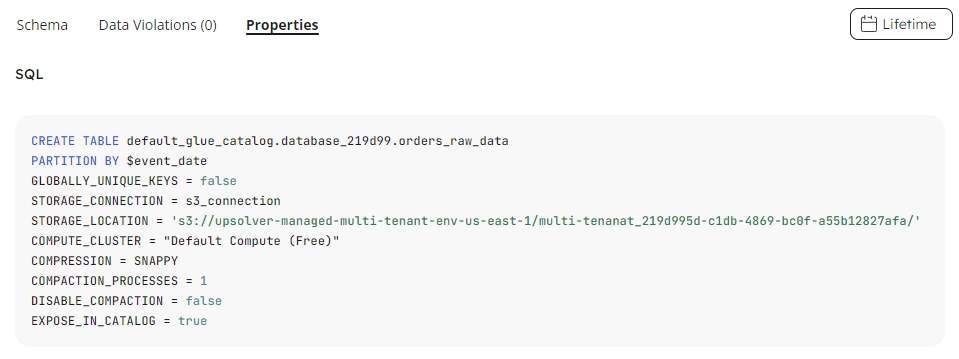
The SQL section is visible for staging tables created in your data lake, and supplies the SQL code used to create the table. Additional default job options may be visible that were not included in the initial code execution, but that Upsolver automatically applies when the table is created:
Options
The Options card displays the table options that were included when the table was created or last altered. Some of the options may include the default values if they were not specified otherwise when creating or altering the table:
The name of the default compute cluster or other cluster.
The partition column used to determine whether the retention period has passed for a given record.
The name of the connection used by the job to ingest the data into the table.
The type of compression for the table data.
Optional number of days that the data will be stored before it is permanently deleted.
Partition keys are part of the primary key to ensure only rows with the same primary key and partition are replaced.
Option to determine if compaction should be disabled.
Default storage location configured for the metastore connection this table is created under.
The specified number of compaction processes your table can do in parallel when it periodically compacts your data.
Learn More
For more information on job options, please refer to the Jobs SQL command reference.
Details
The Details card includes the following information about the selected table:
Description
The optional COMMENT that was included when the table was created or altered, used to describe the table.
Created At
The date and time when the table was initially created.
Last Modified At
The date and time when the table was last altered.
Created By
The login name of the user who created the table.
Last Modified By
The login name of the user who last altered the table.
Id
The GUID assigned by Upsolver to uniquely identify the table.