
Job Settings
This page describes the Job Settings tab for database sources.
The Job Settings tab displays the SQL code used to create the job, alongside job options, and details:
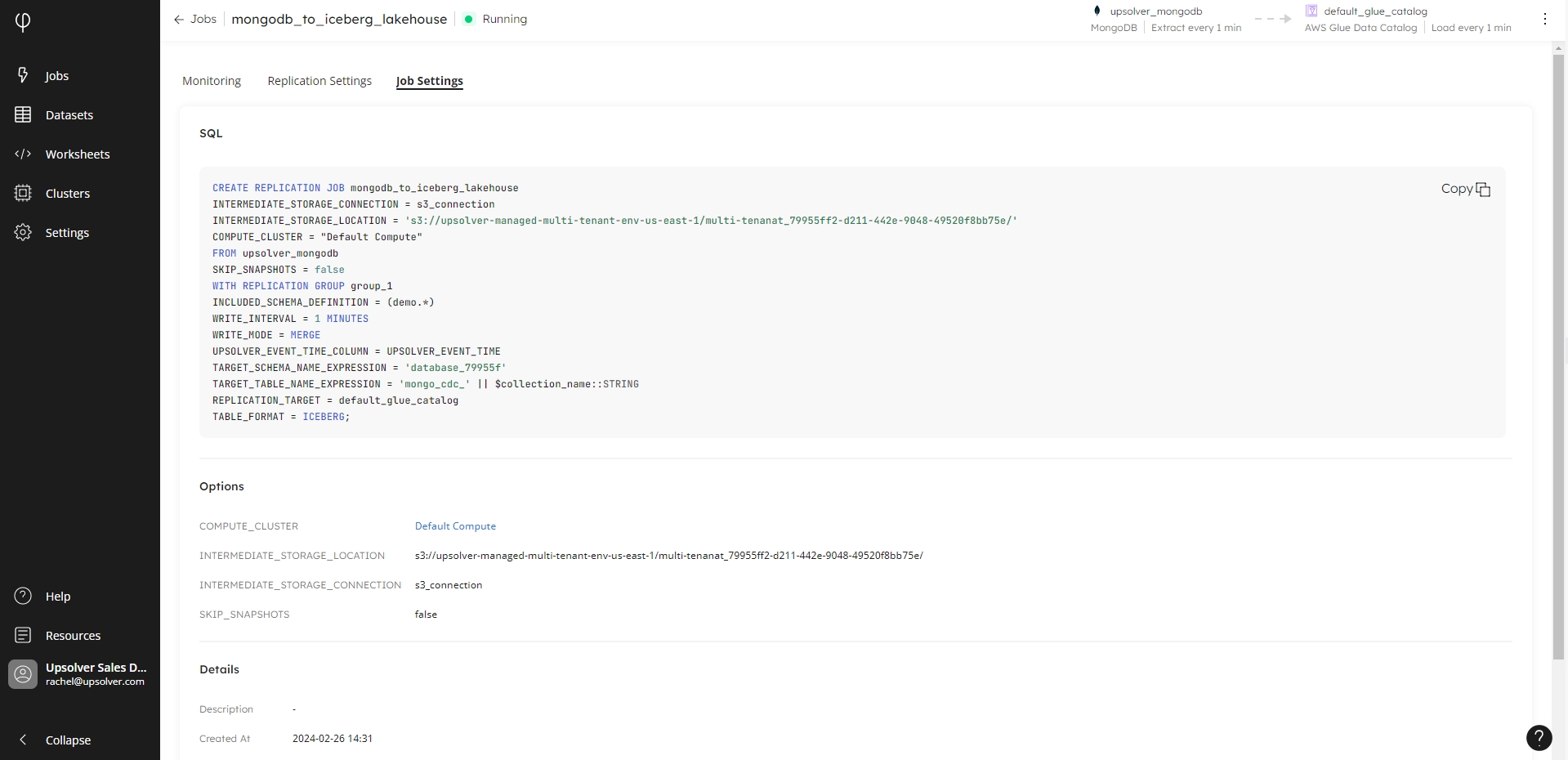
SQL
View the full SQL code used to generate the job. This code includes all job and source options provided when you created the job, or the default options used by Upsolver.
The code can be copied into a Worksheet if you want to re-use it.
Options
The job options provided when you created the job or the default options used by Upsolver - these will vary depending on your source database:
COMPUTE_CLUSTER
The name of the cluster that executes the job.
Click on the link to view further details about the cluster.
HEARTBEAT_TABLE
The name of the heartbeat table for PostgreSQL sources.
INTERMEDIATE_STORAGE_CONNECTION
The name of the connection to stage the data ingested from the CDC source.
PUBLICATION_NAME
The publication name for PostgreSQL sources.
PARSE_JSON_COLUMNS
If true, Upsolver will parse JSON columns into a struct matching the JSON value.
SKIP_SNAPSHOTS
When true, Upsolver will not take an initial snapshot and only process change events starting from the time the ingestion job is created. Otherwise, a snapshot will be taken.
MERGE_PARTITIONED_TABLES
If true, Upsolver will merge the partitioned tables.
INTERMEDIATE_STORAGE_LOCATION
The name of the location to stage the data ingested from the CDC source.
Details
The following details about your job are displayed:
Description
The optional comment provided when the job was created or updated.
Created At
The date and time when the job was initially created.
Last Modified At
The date and time when the job was last updated.
Created By
The username of the person in your organization who created the job.
Last Modified By
The username of the last person in your organization to update the job.
Id
The globally unique identifier for the job.
This Id can be used when querying system.information_schema.jobs and the system.monitoring.jobs tables.
Last updated