
Datasets
Datasets serve as your gateway to performing data observability on your pipelines, and enable you to optimize and monitor the performance of your Apache Iceberg tables.
Real-Time Data Observability
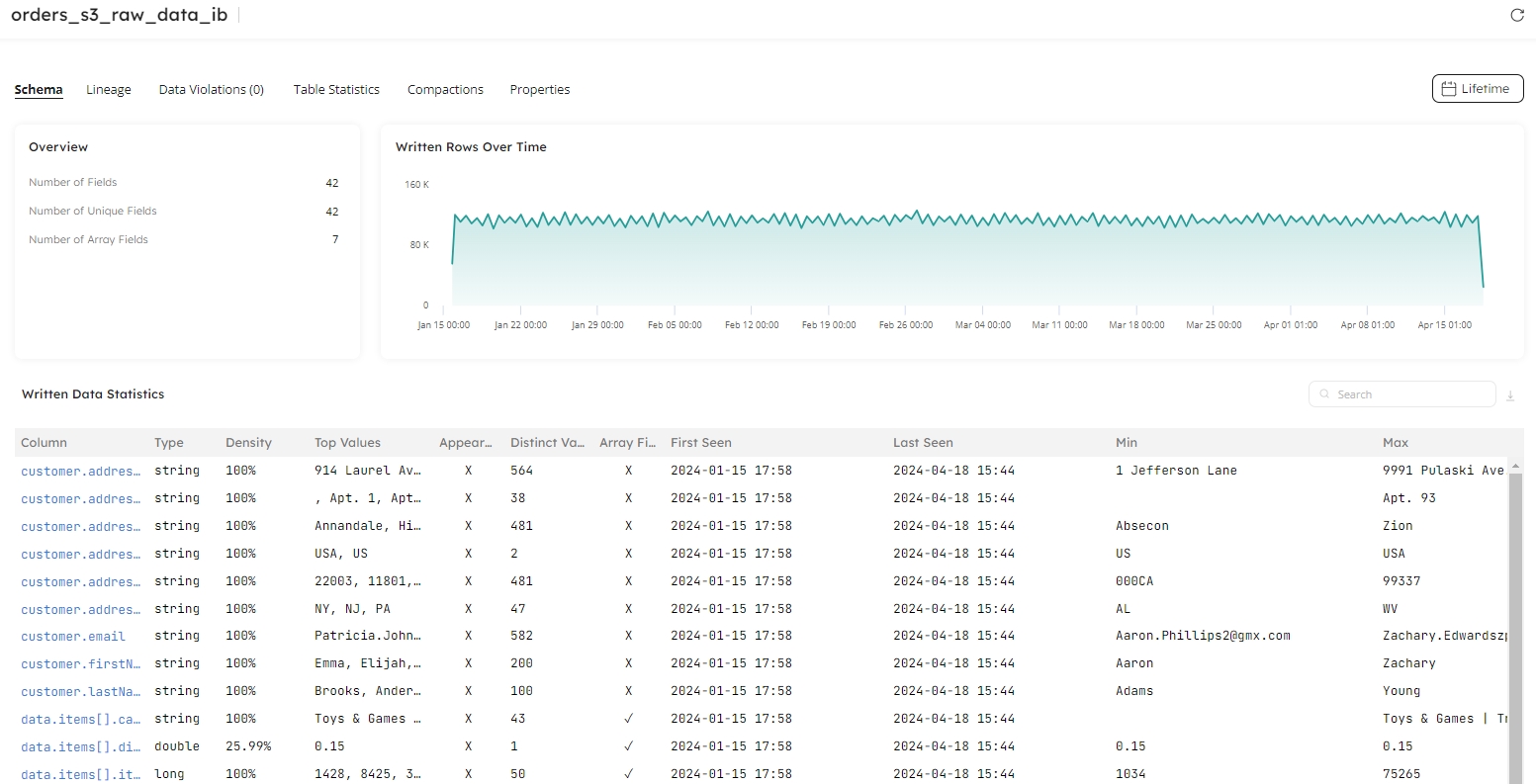
The Datasets tab in Upsolver provides essential insights into your data and tables, enabling you easily to uncover performance problems, and troubleshoot and diagnose data quality issues. These insights are available to everyone in your organization, meaning anyone can drill deep into the data statistics and observe the health of your data.
Whether you're a data engineer responding to end-user queries about the data lineage in your pipelines, or a consumer investigating the freshness of your data, the Datasets tab is your go-to location for data observability.
Using Datasets, you can drill into source data stored in your staging tables in your data lake and lakehouse, and view the data in your analytics targets (if you have created a direct ingestion job, you will only see the target schema). Get the bigger picture and discover where your dataset fits into the wider ecosystem using the Lineage visuals to immediately understand the flow and connection between pipelines and data.
Datasets make it easy to compare the results in your target with the data from your source, so you can quickly trace back to uncover where problems first appeared. The written rows chart delivers instant insight into the volume of data flowing to your staging tables and targets, making spikes and dips in your data easy to identify.
Optimize Apache Iceberg Tables
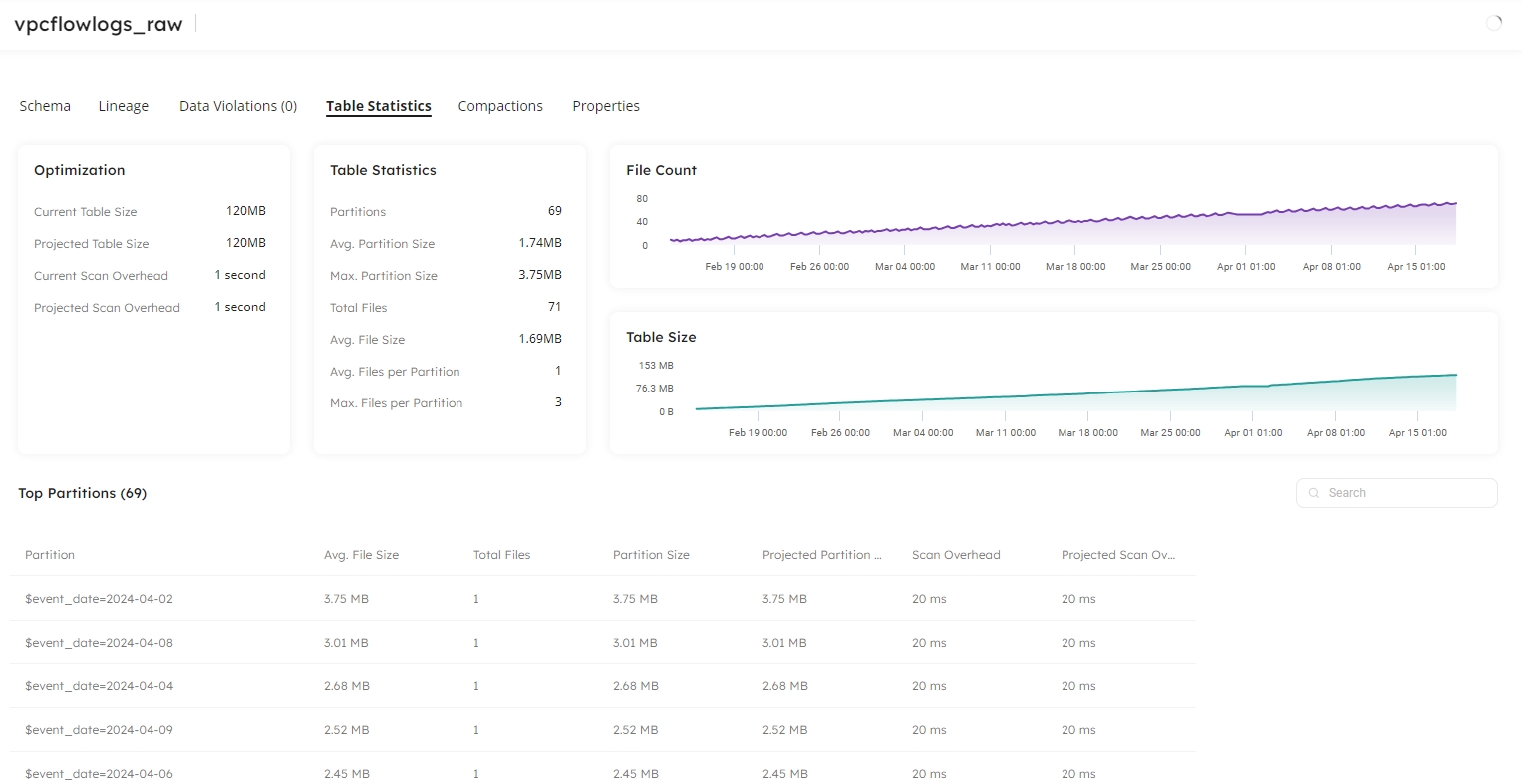
Upsolver supports ingesting data to Apache Iceberg tables, and the optimization of your lakehouse for external tables for data that has not been ingested by Upsolver. Whether you are using Upsolver to create your pipelines or simply to optimize your existing lakehouse, you can view statistics for your Iceberg tables within Datasets. Here, you will discover the storage space savings and performance benefits you will gain when Upsolver has optimized your tables.
When you ingest data to Iceberg using Upsolver, your tables are automatically tuned and compacted for you. If you have an existing lakehouse, you can select the tables you want Upsolver to optimize and compactions are run automatically to deliver continuous performant tables.
Viewing Datasets
To open your datasets, click on the Datasets icon in the sidebar menu in Upsolver. You may want to expand the menu if it is collapsed by clicking on the arrow icon at the bottom of the menu. The entities tree then displays your datasets.
Expand a catalog in the tree to view the schemas and tables. The tree will only display schemas and tables that are ingestion targets for jobs created in Upsolver. Alternatively, use the Search box to find an object: you can search by schema or table name. Click the cross icon in the search box to clear your results and return to the default view.
From the entities tree, you can click on a schema name to view the details for the full dataset, or click on a column name to drill through to view the column level data. The system columns are included to provide you with full observability.
Each dataset provides the following tabs:
Statistics (applicable to Apache Iceberg tables only)
Maintenance (applicable to Apache Iceberg tables only)
Properties (applicable to staging tables in your data lake)
Last updated