
Compactions
The Compactions tab is visible if you have used the Iceberg Table Optimizer to tune your tables, or are using Upsolver to ingest data to Iceberg.
To view Compactions, from Datasets, expand the navigation tree to display the table you want to view. If you are only using Upsolver to manage Iceberg tables you have created using another tool, you will only see the tables currently selected for optimization. If you have created pipelines using Upsolver, you will see all your datasets within the navigation tree.
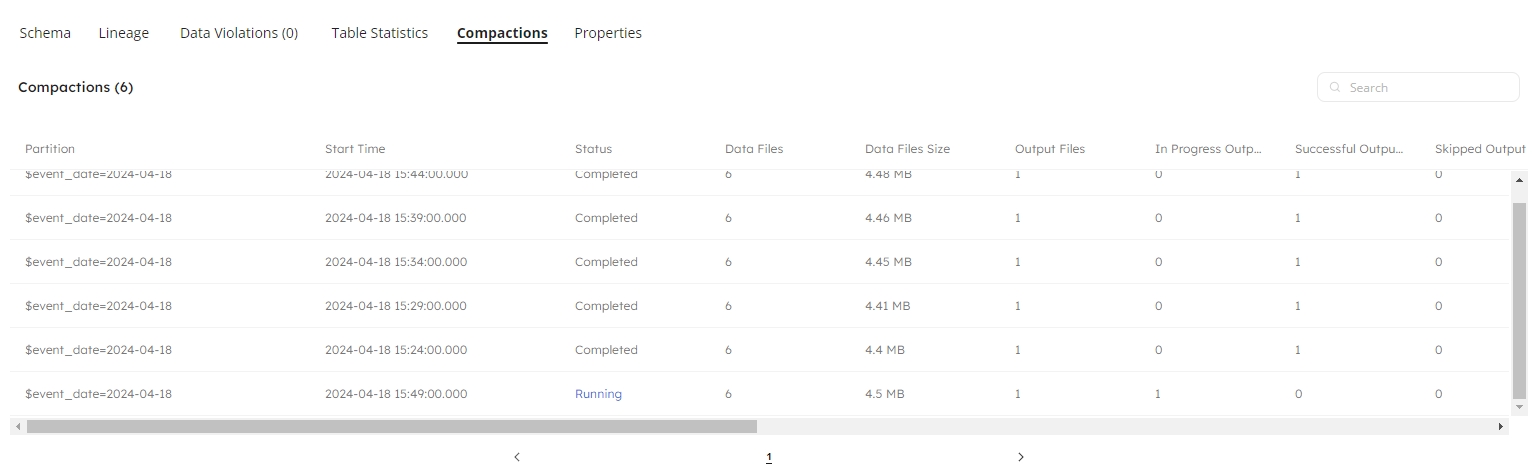
Compactions
The Compactions table provides a wealth of information to help you understand where data is being written into your partitions, and where equality and position deletes are occurring.
Partition
The partition containing some or all of its files undergoing compaction.
Start Time
The start time of the compaction process.
Status
The current status of the compaction process, which can either be Completed, Running, or Failed.
Data Files
The number of data files scheduled for compaction.
Data Files Size
The total size of data files scheduled for compaction.
Output Files
The projected number of data files after the compaction is complete.
In Progress Output Files
The number of target data files currently being compacted.
Successful Output Files
The number of target data files successfully compacted.
Skipped Output Files
The number of target data files aborted during compaction due to deletion applied after the compaction process has begun. The compaction will be rerun on its next schedule.
File Size Reduction
The size reduction achieved by the compaction process. Formula: (Data Files Size + Position Deletes File Size) - Written Bytes.
Equality Deletes Files
The number of equality deletes files to apply while compacting the data. Equality deletes files are files that contain delete commands by primary keys. During the compaction deletes files are being handled.
Equality Deletes Files Size
The total size of Equality Delete Files applied during compaction.
Position Deletes Files Size
The number of position deletes files to apply while compacting the data. Position deletes files are files that contain delete commands by data file name and index.
Read Rows
The number of rows to read from the data files.
Read Bytes
The size in bytes of rows read from the data files.
Written Rows
The number of rows written to the output data files during compaction.
Written Bytes
The size in bytes of data written to the output data files during compaction.
Run Time
The CPU time used for compacting the data. Upsolver parallelizes the compaction process up to the number of output files.
The Compactions tab includes a Search box to enable you to drill into one or more specific partitions that you want to view statistics for. Type in the name of the partition, or part-name for multiple partitions, and click Enter. You can also click on the Filter icon to find partitions matching specific metrics.
To explore your compaction metrics outside of Upsolver, optionally search or filter for the partitions you want to view, and click the Download icon to save the results to a CSV file.