
AWS Glue Data Catalog
Follow these steps to use AWS Glue Data Catalog as your target.
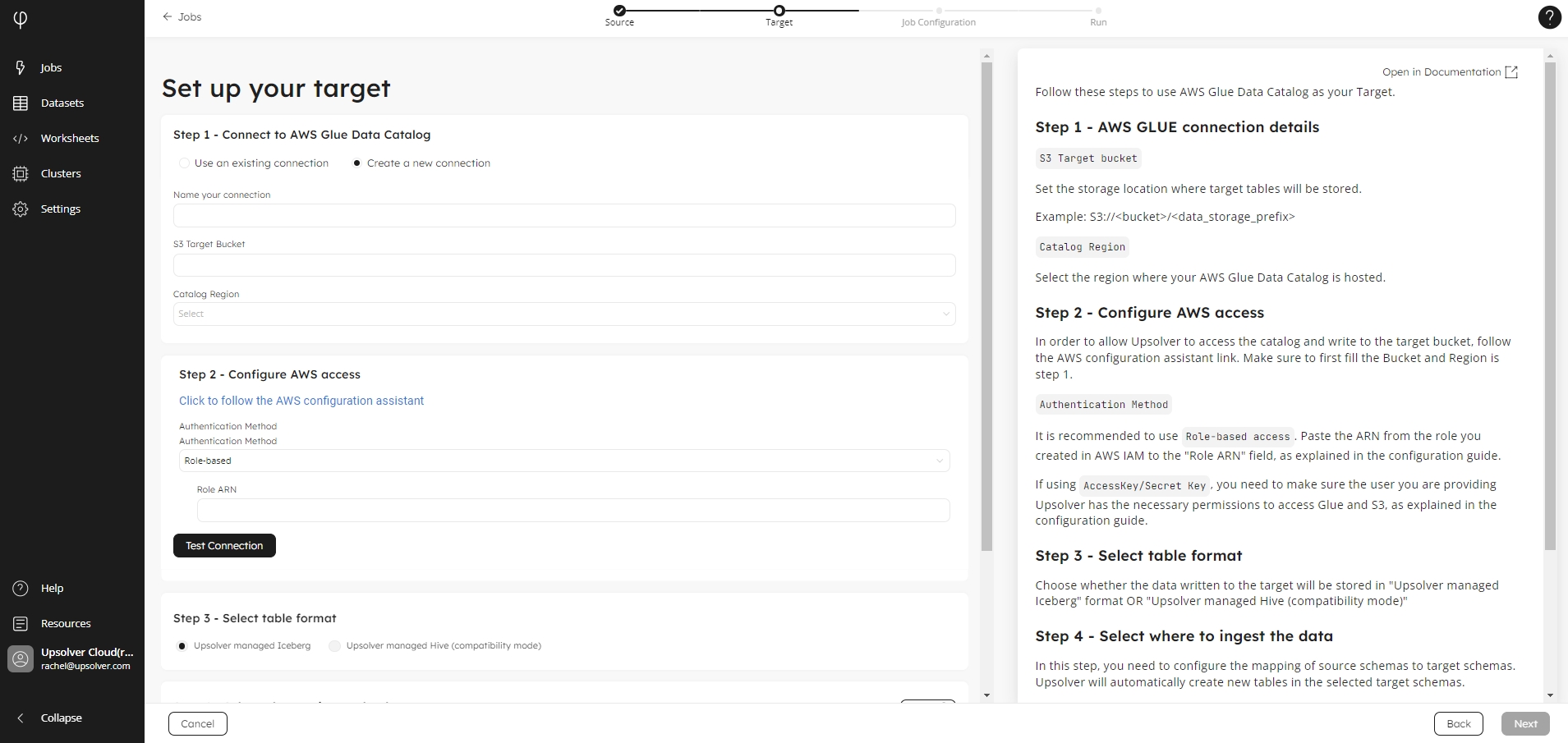
Step 1 - Connect to AWS Glue Data Catalog
Create a new connection
Click Create a new connection, if it is not already selected.
In the Name your connection field, type in the name for this connection. Please note this connection will be available to other users in your organization.
Set the storage location where target tables will be stored in the S3 Target Bucket field, using the format:
S3:///<data_storage_prefix>
Select the region where your AWS Glue Data Catalog is hosted in the Catalog Region select list.
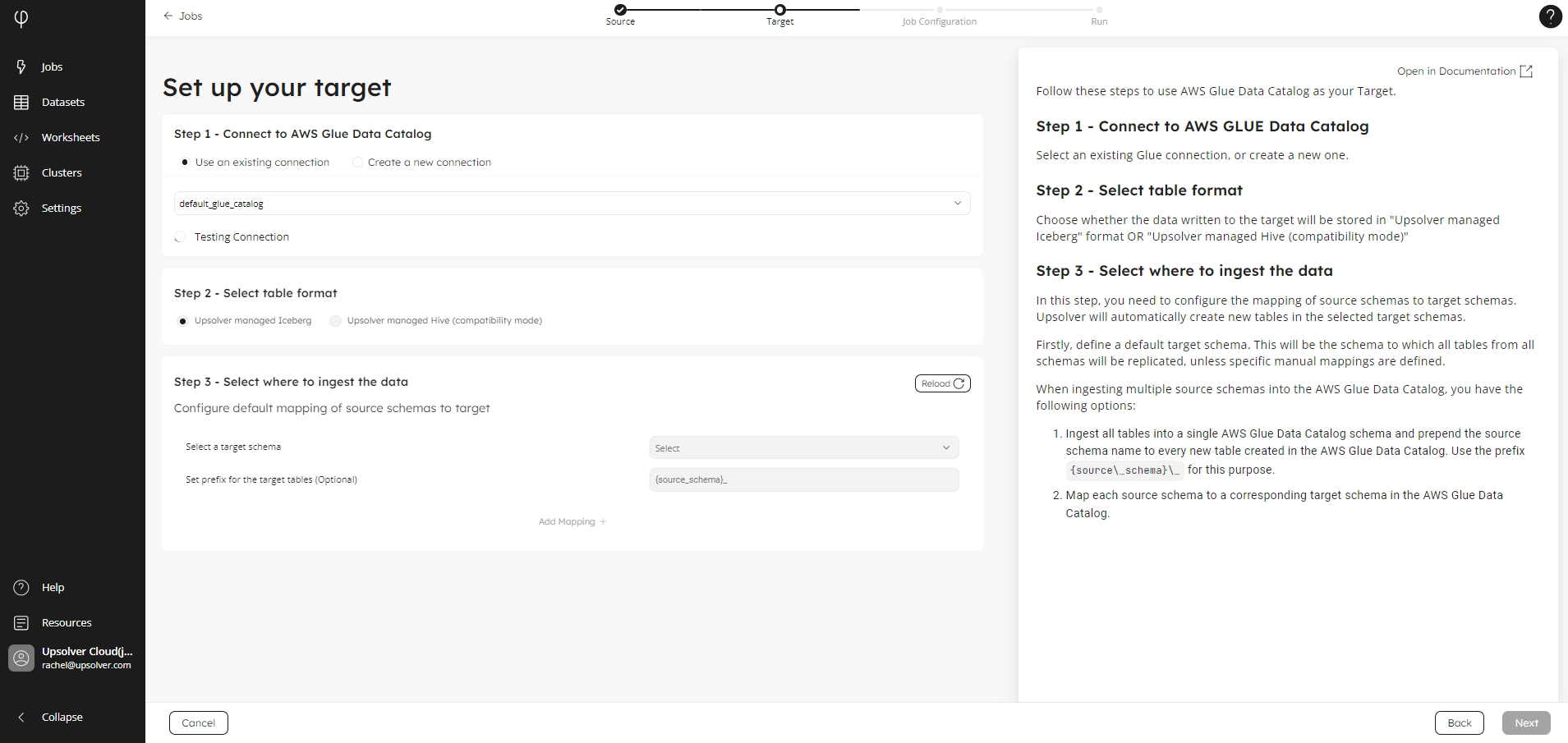
Use an existing connection
By default, if you have already created a connection, Upsolver selects Use an existing connection, and your AWS Glue Data Catalog connection is populated in the list.
For organizations with multiple connections, select the target connection you want to use.
Step 2 - Configure AWS access
In order for Upsolver to access the catalog and write to the target bucket, follow the AWS configuration assistant link.
For the Authentication Method, we recommend to use Role-based access. Paste the ARN from the role you created in AWS IAM into the Role ARN field, as explained in the configuration guide.
If using AccessKey/Secret Key, ensure the user provided to Upsolver has the necessary permissions to access AWS Glue Data Catalog and Amazon S3, as explained in the configuration guide.
Step 3 - Select table format
Choose the target format to stored your data:
Upsolver managed Iceberg
Upsolver managed Hive (compatibility mode)
Step 4 - Select where to ingest the data
In this step, you need to configure the mapping of source schemas to target schemas. Upsolver will automatically create new tables in the selected target schemas.
Firstly, define a default target schema. This will be the schema to which all tables from all schemas will be replicated, unless specific manual mappings are defined.
When ingesting multiple source schemas into the AWS Glue Data Catalog, you have the following options:
Ingest all tables into a single AWS Glue Data Catalog schema and prepend the source schema name to every new table created in the AWS Glue Data Catalog. Use the prefix
{source\_schema}\_for this purpose.Map each source schema to a corresponding target schema in the AWS Glue Data Catalog.