
Using the Wizard
This quickstart shows you how to use the Wizard to create ingestion jobs.
The Upsolver Data Ingestion Wizard is the easy, no-code option for ingesting your data into Amazon Redshift, AWS Glue Data Catalog, ClickHouse, Polaris Catalog, and Snowflake. Use the Wizard to create a job, or use the auto-generated code as a basis for creating more advanced use cases by extending the functionality using familiar SQL syntax.
For Elasticsearch, Amazon S3, and PostgreSQL targets, the Wizard will provide a code template for configuring your connections and job, based on the data source you select.
The Wizard creates a job in four simple steps:
Create a job with the Wizard
Login to your Upsolver account and, from the left-hand menu, click Jobs. On the Jobs page, click the Create New Job button. This opens the Ingestion Wizard. Click on the card for the data source from where you want to copy your data and the card for your data target:
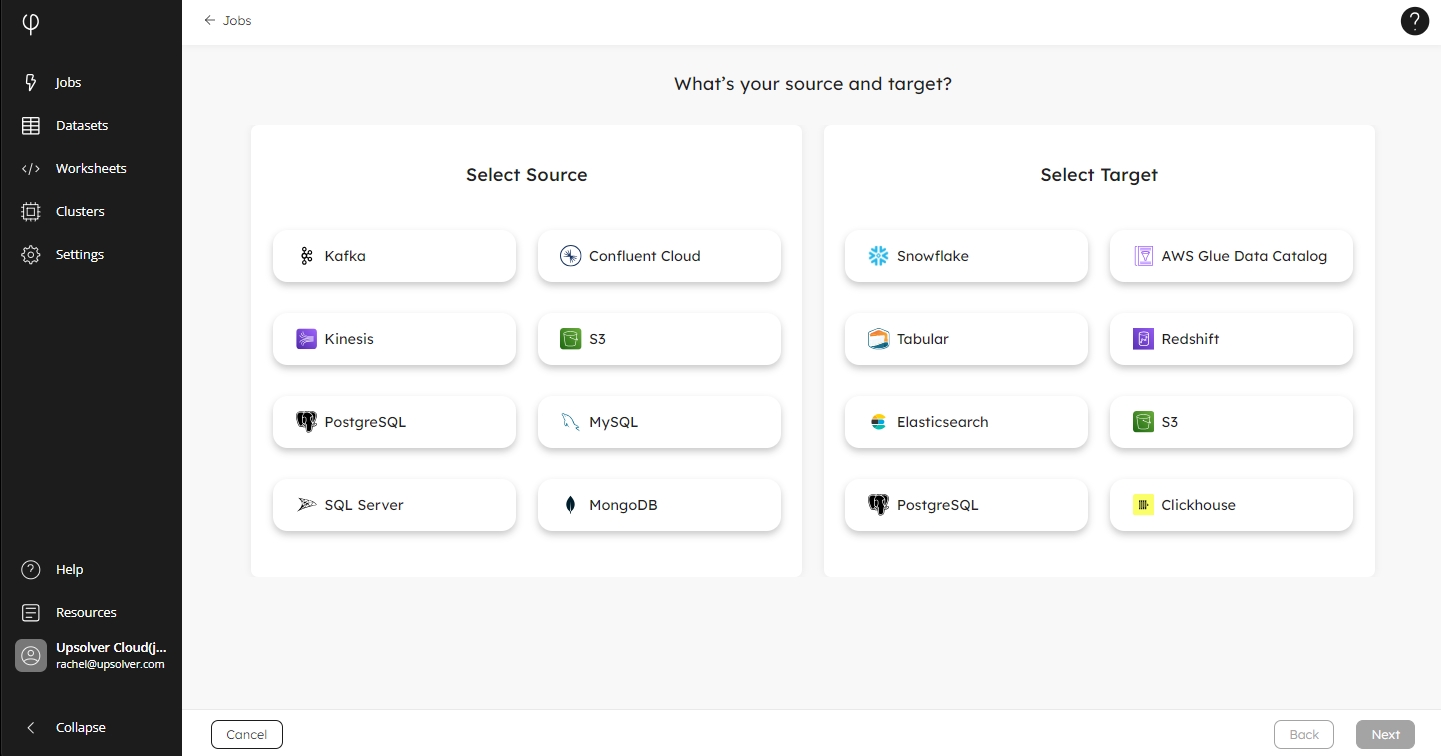
Set up your source
The Wizard guides you through the steps for setting up your data source:
Set up your target
Follow the guide for setting up your target:
Configure the ingestion job
Upsolver supports various data sources, from files, streaming, and CDC data. Follow the applicable guides for configuring your job based on your source:
Review and run the job
The Wizard auto-generates the SQL code for creating your job, and sub-jobs where applicable. You can open this code in a query window, and enhance the job using advanced features.
Last updated