
Observe Data with Datasets
The guide shows you how to monitor the quality and freshness of your data in real time using Datasets.
Datasets in Upsolver provide powerful information to enable you to observe the flow and volume of your data, check for quality issues, and uncover changes to your source schema. These statistics are built in as standard in Upsolver, saving you the time and expense of having to query your data warehouse or acquire additional resources to build custom reports. However, if you want to run your own queries, we also provide system tables you can interrogate for your custom use cases and reporting.
Datasets enable you to:
View staging table and output/destination schemas
Monitor data health, freshness, and volume when loaded into the destination
Track data lineage from the target back through to source
Monitor data quality violations
The following guide illustrates how to create a staging table and ingestion job to copy data from Amazon S3, and then use the Datasets feature to observe your data. You will then add an expectation to your job to capture data quality violations. Follow these steps to learn how to:
Create a connection to Amazon S3.
Create a staging table in your data lake.
Create an ingestion job to copy data from Amazon S3 to your staging table.
Profile your data in the Datasets view, and learn how:
Understand your dataset schema
Monitor data volumes
Profile your schema
Check for data freshness
Detect schema evolution
Understand column-level statistics
View the data lineage for your job to see the journey of your data
Alter your job to add an expectation to catch data quality issues that you don't want to reach your data warehouse.
View the properties of your staging table.
Step 1
Create a connection to Amazon S3
The first step is to create a connection to our Amazon S3 bucket. This connection gives you the ability to configure the AWS IAM credentials that Upsolver needs to access the data.
Here's the code:
CREATE S3 CONNECTION my_s3_connection
AWS_ROLE = 'arn:aws:iam::111111111111:role/<upsolver-role-*>'
EXTERNAL_ID = '12345678'
READ_ONLY = TRUE;For more information, please see the guides to configure Amazon S3 and create a connection.
Step 2
Create a staging table
Next, we will create a table named orders_raw_data to stage our ingested data. In the code below, notice that we haven't specified any columns. The open brackets instruct Upsolver to infer the schema and types for us during ingestion. Upsolver will continue to manage schema evolution over time so we don't have to manually contend with this every time a change is made to the source.
Optionally, you can define the columns in your staging table: the CREATE TABLE SQL reference includes instructions for adding columns. The following example includes an optional comment to describe the purpose of the table.
Here's the code:
CREATE TABLE default_glue_catalog.upsolver_demo.orders_raw_data()
PARTITIONED BY $event_date
COMMENT = 'Staging table for raw orders from S3';Your table is now visible in the Entity tree in the Upsolver query engine window. If you expand the table and column nodes in the tree, you will notice that the table has been created with Upsolver's default system columns, but no data columns. These will appear after we create our ingestion job in the next step.
Step 3
Create an ingestion job
Now that we have created our staging table, the next step is to populate it with our data from Amazon S3, so let's create an ingestion job. In the example below, we create a new job named ingest_orders_to_staging that copies the data from the source specified in the LOCATION option, using my_s3_connection to connect.
Here's the code:
CREATE SYNC JOB ingest_orders_to_staging
COMMENT = 'Ingest raw orders from S3 to staging'
CONTENT_TYPE = AUTO
AS COPY FROM my_s3_connection
LOCATION = 's3://upsolver-samples/orders-with-evolution'
INTO default_glue_catalog.upsolver_demo.orders_raw_data;The CONTENT_TYPE job option is set to AUTO, instructing Upsolver to ingest all files that are discovered in this location. If you want to ingest a specific file type, such as CSV or JSON, you can define it here.
When we run the code to create the job, Upsolver infers the schema and data types, and creates the columns in our staging tables. You will see the columns appear in the Entity tree, and data will start flowing in. This may take a few minutes.
Step 4
Profile your data in the Datasets view
Now that our data has been ingested, we will dive into the statistics. From the main menu, click Datasets. In the Connections tree, expand the glue catalog and database nodes to display the orders_raw_data dataset. Click on orders_raw_data and the Schema tab appears. This provides us with instant visibility on our data.
In the Schema tab, under the name of your dataset, you will notice the Table Last Update value tells us when this table was last written to. The Overview card informs us of the number of fields in the dataset, including system columns, the count of fields with unique values that could be candidates for a primary key, and how many columns are arrays.
Monitor data volumes
Let's look at the flow of data into our dataset. The Written Rows Over Time visual enables us to monitor ingested data, and detect spikes or drops in the volume of events. The default view is all events over the lifetime of the job:

We can change the timescale displayed in this chart to see ingested data volumes in more detail. Click the Lifetime button, and select Today. The chart is updated to show ingested events since midnight (UTC) time until now:

By drilling into our data volumes, we can discover the date and time when unexpected volumes occurred, and troubleshoot the reasons behind the spikes and falls. Hold your mouse over a spike or dip to view the number of ingested events and the exact timestamp.
Profile your schema
The Ingested Data Statistics table provides a wealth of information that is especially useful if you used Upsolver to infer your schema and types. The Column name and Type are the values inferred by Upsolver, or defined when the table was created. You can click on the linked column name to drill through to column-level statistics.
The Density column represents how full the column is, so for fields that should be fully populated, you would expect the value to be 100%. The Top Values column shows the three most common values in each column, which can help us detect anomalies. For example, in our dataset below, we can see the customer.address.country column has a value for USA and US. This would likely cause downstream issues in our data warehouse, so discovering data discrepancies enables us to take action to fix them:

However, we can also see that the three most popular customer.address.state values are NY, NJ, and PA. The Has Value Repetitions column uses a tick or cross icon to denote if this field has unique values and could be a primary key. Use this in combination with the Distinct Values column to discover uniqueness.
If you have array values in your field, a tick icon is displayed in the Array column, otherwise this is represented as a cross. The First Seen and Last Seen columns inform us when data was first and last seen, while the Min and Max values give us the top and bottom values in the column - this applies alphabetically to string data, and the smallest and largest values for numeric data.
Download this Data
Click the download icon to the right of the Search box to download your table inspections CSV report and profile your dataset outside of Upsolver.
Check for data freshness
The Table Last Updated value informs us when our dataset was last written to. We can dive in deeper to see when each column in the table was last updated in the Ingested Data Statistics table. The First Seen column tells us when we first saw data in this column, while the Last Seen column will help us discover when this column was last updated. If an end-user has noticed that data has not been refreshed in a dashboard, you can track the problem back to find out when data last appeared and investigate the cause of the problem.
Detect schema evolution
The Ingested Data Statistics table helps us uncover schema evolution in our pipelines. In the following example, while looking at the statistics for our dataset, we notice that the Density of customer.address.phoneno is only 0.20%, meaning there is very little data in this column. In some instances, this may be your expectation, but in our example, all customers should have a phone number as this is a required field in our source e-commerce system:

The First Seen column informs that this row first arrived four minutes after the rest of the data, and Last Seen shows that is has not been updated in line with other rows. Notice the row below: the customer.address.phonenumber column has only 99.80% density. However, when combined with customer.address.phoneno, this gives us our 100% density. We can see that a new row was added and data started flowing into that column, thereby causing the issue.
Understand column level statistics
Our column names in the Ingested Data Statistics table are hyperlinked and we can drill into column-level statistics. Imagine that a user has reported an issue on the state dimension in the data warehouse and we need to investigate. If we click on customer.address.state, we can delve into these values to check what's going on.
The Overview card shows us we have 100% density in the column as expected, and 47 distinct values, so we know we haven't surpassed the maximum of 50 states we can have for our North American customers. The Min Value shows us the minimum value based on alphabetical ordering, in our case, AL. The Max Value is WV, and the Last Seen value of 2 minutes ago confirms the data is fresh:

If we look at the String Length Distribution graph, we can instantly see we have a problem. We are expecting all state values to have a character length of 2, so the chart should display a single pillar to reflect this. As we can see, we have rows containing values up to 13 characters:

The Top Values card can help us uncover the spurious values. If we scroll through the listed values, we can see the distribution of data across the states and find the incorrect data:
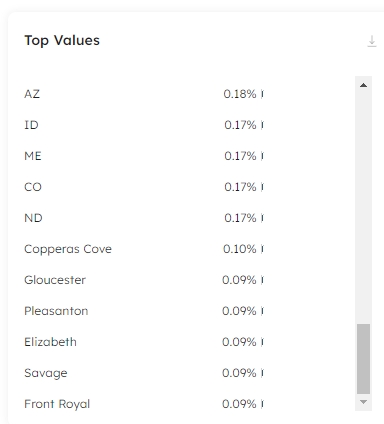
It is easy to identify the incorrect data: clearly Copperas Cove through to Front Royal are not US states. We can't correct this problem in the source, but we can add an expectation to our job to check for it in future ingestions, which we will do in the next step.
Download this Data
Click the download icon in the top right-hand corner of the Top Values card to download your column inspections CSV report and profile your data outside of Upsolver.
Step 5
View data lineage
Next, we will look at the journey our data took to get from source to target. In Datasets, click on the Lineage tab. You will see a diagram showing the points where your data travelled:

We can see that our data originated in our S3 bucket, was then ingested by the job, and landed in our target table in our AWS Glue Data Catalog. Click on Display Extended Lineage, and if the dataset is connected to other pipelines, you will see where it fits in:

As the diagram above displays, the data in our source bucket is also written to another destination, dataset_s3, in our data lake.
If we created another job to write orders from Apache Kafka, for example, into our orders_raw_data table, the Lineage tab would show that we have multiple pipelines writing to our target dataset:

In this example, we see that another job is is writing the orders topic from an Apache Kafka source into our orders_raw_data table.
Click on the orders_raw_data dataset to display the information pop-up: 
This tells us the name of the table and schema, and the connection used by the job to write the data. Click on Info to display the pop-up:

The Schema tab provides a quick view of the data, and the SQL tab contains the syntax to create the job. Optionally, you can click Copy, and paste the code into a worksheet.
Step 6
Add an expectation to your job
In Step 4, we learned that ingesting incorrect values into our state column is causing issues in our downstream data warehouse state dimension. To prevent these rows from reaching our data warehouse we can create an expectation. Expectations can be added to an existing job without needing to drop and recreate the job, meaning we can implement our data quality rules immediately when identifying an issue.
In the following example, we add an expectation named exp_state to our ingest_orders_to_staging job.
Here's the code:
ALTER JOB ingest_orders_to_staging
ADD EXPECTATION exp_state
EXPECT LENGTH(customer.address.state) = 2
ON VIOLATION DROP;This expectation defines that we are expecting the customer.address.state data to have a character length of 2: if this expectation is not met, we drop the row from our pipeline (it remains in our source S3 file) and does not reach our orders_raw_data staging table.
Expectations are a powerful feature for identifying data quality issues, and it is likely we will want to keep an eye on the data violating our requirements. Datasets includes a Data Violations tab for monitoring expectations added to jobs ingesting data to data lake tables, as well as to target tables such as Snowflake.
In the Datasets Connections tree, click on orders_raw_data. Having added one or more expectations to your job, you will now see a count of expectations in the Data Violations tab header. If you have multiple jobs writing to your table, expectations across all jobs are included here:

Our new expectation is now visible, and count of violations will update when our data quality rule is violated.
Expectations
Please read the article on Expectations to learn more and discover how to build a custom reporting solution to monitor captured data warnings and violations by following the how-to guide on Managing Data Quality - Ingesting Data with Expectations.
Step 7
View dataset properties
If your dataset is stored in the data lake, you will see the Properties tab displayed for your dataset. Click on the tab to open it. and look at the SQL code used to create the job. You may notice that Upsolver has included additional job options with default values. These options are also listed in the Options table along with additional settings. The Details list shows the username who created the table, the user who last modified the table, and the datetime stamps when the table was created and last updated.
Conclusion
In this how-to guide, you learned how to ingest data from Amazon S3 to a staging table and use the Datasets feature to observe your data and troubleshoot problems. You learned how to look for spikes and dips in the number of events flowing through your pipeline, and how to check on the dataset schema that was inferred and created by Upsolver. Then you learned how to detect schema evolution, and how the column-level statistics can help you uncover quality issues in your data. Lastly, you learned how to add an expectation to your job to ensure ingested data is in the correct format and does not pollute your data warehouse, and view the properties for your table.
Try it Yourself
To use the Datasets feature to observe the data in your source and target datasets:
Ingest data to a staging table in your data lake, or to your output such as Snowflake.
Open Datasets to view schema and column statistics, observe the volume of data flowing through your pipeline, and check data freshness and quality.
Download table and column inspection reports to view your schema and data statistics.
Create an expectation on your job to check for data that violates your quality rules.
Learn More
To learn more about data observability in Upsolver, please see the Datasets reference.
If you want to query the underlying Dataset tables, please refer to Insights.
Last updated