
Ingest Data Using CDC
This page describes the process for ingesting data from relational database sources.
Upsolver embeds the Debezium Engine v.2.2.1, a mature, battle-tested open-source framework for change data capture (CDC) from transactional databases. The embedded solution is designed to provide fast, reliable, and consistent integration between your business-critical databases and your data lake and data warehouse. Because Upsolver embeds the Debezium engine, you don’t need to manage or scale additional hardware, Upsolver automatically scales resources to meet demand. Additionally, the embedded integration eliminates external failure points, delivering a fast, reliable, and consistent stream of events.
The following diagram illustrates how Upsolver embeds the Debezium Engine:
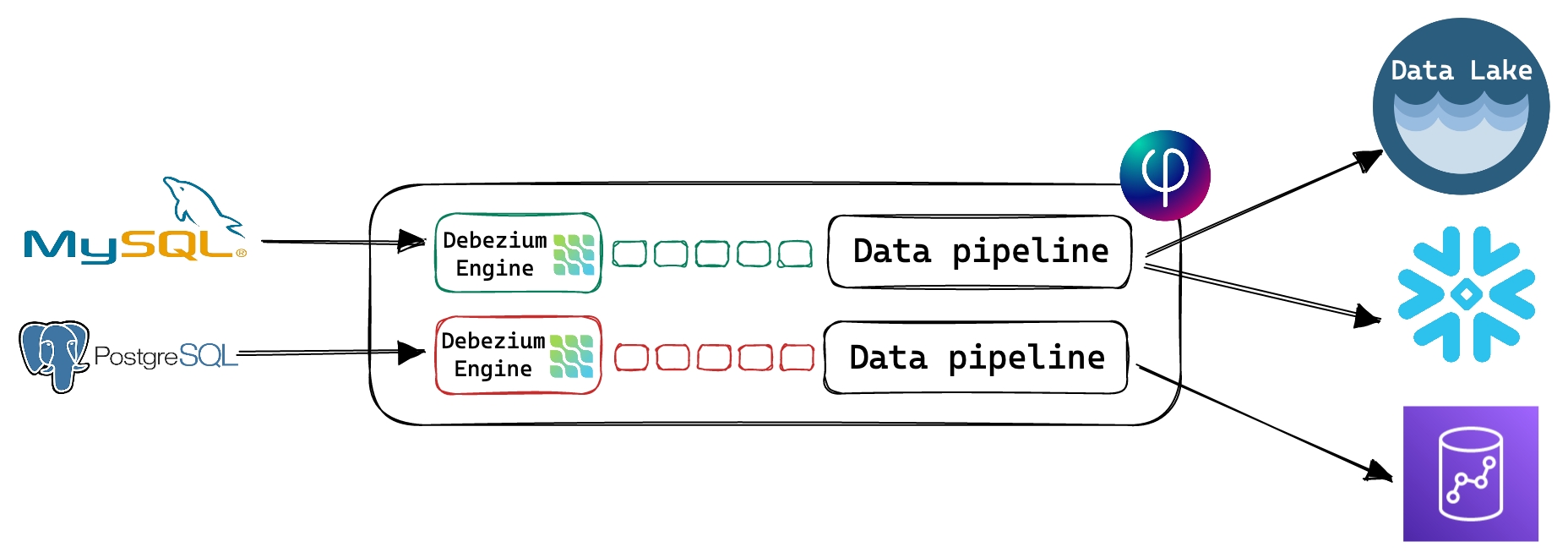
Supported database connectors
The following databases are currently supported. Select each one to see the available job configuration options:
Microsoft SQL Server
MongoDB
MySQL
Database integration overview
Enable: Turn on CDC in your source database by creating a replication user and enabling the appropriate CDC configuration. Follow the setup instructions outlined in each section related to your database of choice.
Connect: You create a connection to your source database with the appropriate access credentials
Ingest: You create an ingestion job defining which tables to replicate, or default to all tables.
Initial sync: Upsolver automatically discovers selected tables, takes a snapshot, and begins to replicate historical data. The duration of the initial sync is dependent on the number of source tables and their size.
Load: Upsolver combines the change events from all selected tables into a single, wide, immutable, append-only table that is stored in the data lake. This staging table contains all of the raw change events, partitioned by the full table name.
Update: You create a transformation job that selects a specific source table from the staging table and writes to your target data lake or data warehouse table. Upsolver inserts, updates, and deletes rows using a primary key.
Enable CDC for your database
Follow the instructions for your preferred database to enable Change Data Capture.
Connect Upsolver to your database
At Upsolver, we take data security very seriously and it is a key reason that companies choose to use Upsolver for data ingestion and movement. To connect Upsolver to your database, please follow the steps to integrate it with your AWS account and VPC.
Having deployed and integrated your AWS VPC, you can establish a secure connection between Upsolver and your databases.
To connect, follow the instructions in the CREATE CONNECTION section. A connection in Upsolver is persistent, which means that after it is created, you can reuse it any time you need to connect to your database. Furthermore, the connection can be used by other users in your Upsolver organization.
Ingest CDC data into the data lake
An important best practice is to stage all of the raw data in the data lake prior to modeling, transforming, and aggregating it. The raw data can be archived, or used to validate data quality, perform ML experiments, and be reprocessed in case of future needs to correct issues or enrich the data.
To ingest CDC events into the data lake, you need to create a target table and then create an ingestion job that will copy CDC events into the target table. When you configure the ingestion job, you can choose to ingest a single table, a few tables, or all tables in your database. Furthermore, you can alter the ingestion job at a later point in time to add or remove tables to be ingested.
Initial sync of historical data
When you set up a CDC integration between your source database and Upsolver, start by copying all of the historical data in your tables. When you create an ingestion job, Upsolver automatically takes a full snapshot of each table you selected and begins to copy those records to the data lake. This process can take from a few minutes to multiple hours depending on the size of your source tables and the current load on the database.
Upsolver ensures not to starve database resources when syncing the initial snapshots of tables. If you choose, you can configure your ingestion job to not take a snapshot by setting the SKIP_SNAPSHOTS property, but that is not recommended unless you have a good reason.
Loading events into the data lake
Upsolver stores all CDC events, historical from snapshots and new changes, in a staging table in your data lake. This table is partitioned by the fully qualified table name, databaseName.tableName.
The table schema is a union of all columns from all tables ingested. Columns use fully-qualified names: databaseName.tableName.columnName. This immutable, append-only table represents the change log of all the tables you selected to ingest. When new tables are added to the ingestion job, new partitions will be created and the schema expands to include new columns. It is best practice to partition your staging table by date, in addition to the table name, for faster querying and filtering results.
If you have hundreds or even thousands of tables in your source database, you can choose to create multiple ingestion jobs, each processing a smaller number of tables. You can select which tables an ingestion job will process using the TABLE_INCLUDE_LIST property.
Update your target table with new CDC events
After the staging table is populated with the changelog of your source tables, you can create a transformation job that will select specific tables of interest, and model, transform, and load them to your preferred target, such as the data lake or data warehouse. Your transformation job will write the output into another table. Ensure that the target table is configured with a primary key to enable Upsolver to enforce primary key constraints resulting in rows being correctly updated.
Last updated