
Core Components
This article describes Upsolver's core components and how they interact with each other.
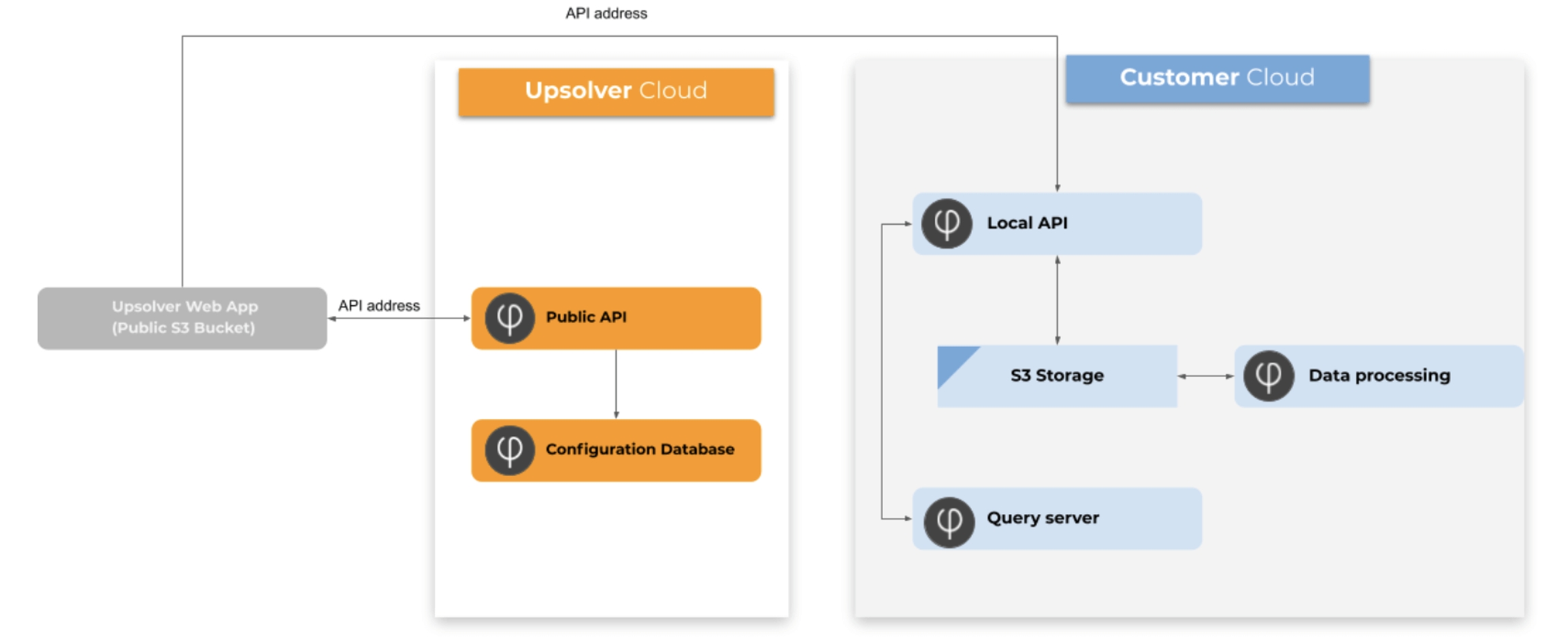
The Upsolver Compute Cluster is a group of EC2 instances that are responsible for data processing. These servers provide the compute power for transforming, aggregating, and enriching data in Upsolver. They don’t interact with outside processes. The instances poll work and process the data, then write the data to Amazon S3.
Resources
Kinesis Stream
Upsolver uses the Kinesis Stream to enable all servers to communicate with each other. They do so by reporting information directly to Kinesis; they do not communicate with each other. Each server polls data from Kinesis to discover information about other servers.
All servers exchange information with the Kinesis Stream to communicate state and to synchronize the work between the servers running in the account. This applies to:
Upsolver's fully-managed architecture deployed in Upsolver’s environment
Private VPC deployment architecture deployed in your AWS account
Metadata Store
The Metadata Store is a global component for Upsolver's fully-managed deployment model and for the private VPC deployment model. It is a centralized space to store the configurations. If you create an object in Upsolver, Upsolver always stores the definitions in the global metadata store. The metadata store is a key-value store that the clients communicate using the API server. Clients don’t interact with the Metadata Store directly. Outgoing traffic goes through the API server for the purpose of storing and requesting information from the key-value store. The same entities are reflected on Amazon S3 in the user’s account to provide durability. The production servers only poll data from Amazon S3. In the unlikely event that the global environment is unavailable, there is no impact on any data being processed.
The servers report to several Kinesis streams, including the status of the tasks and operational metrics such as CPU and memory. It keeps track of servers’ health and the information is used to replace servers if necessary. Servers report some of the metrics directly to the user's CloudWatch environment, which is used for scaling and auto-healing of the cluster. The metrics are also used for spinning servers up and down. Servers report additional metrics, such as billing information and telemetry data, to Upsolver-managed Kinesis streams. The data reported directly to CloudWatch is operational data about the servers.
Logs and environment
By default, Upsolver sends application logs to a centralized location for easy debugging from an Upsolver bucket. Optionally, you can choose to send the logs to your own dedicated bucket if you want direct access to the logs.
The Upsolver environment polls data from various locations. Environment configurations including geo IP map and user agent map files are polled from global configurations as well as from static initialization files. They’re polled from various buckets on Amazon S3. During the initialization phase, the servers also install components such as Java and Docker containers polled from Upsolver’s Docker Hub repository. Servers also report to the monitoring infrastructure (InfluxDB).
Upsolver’s web interface is hosted on a CDN out of an Amazon S3 bucket. The web interface accesses the private API directly to populate the entities.
Operations
File-based data
Upsolver lists the files that it reads from the source and then creates a list of all files that need to be loaded. By default, the poll operation executes every minute. Upsolver then takes the list of files, parses the data, and pushes them into a parsed folder. The parsed folders are the same for both file-based and event-based data.
For file-based data sources, Upsolver reinforces exactly-once semantics by:
Sending metadata on which files exist.
Storing which files exist in the Kinesis stream.
Reading existing file information from the Kinesis stream to ensure exactly-once processing.
Event-based data
For event-based data sources, Upsolver reinforces exactly-once semantics by:
Finding the events up until which timestamp/offset have already been polled.
Writing the information to the Kinesis stream.
Reading offset information from the Kinesis stream to ensure exactly-once processing.
Last updated